PPO 在原目标函数的基础上添加了 KL divergence 部分,用来表示两个分布之前的差别,差别越大则该值越大。那么施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较大的目标函数。
TRPO 与 PPO 之间的差别在于它使用了 KL divergence(KL散度)作为约束,即没有放到式子里,而是当做了一个额外的约束式子,这就使得TRPO的计算非常困难,因此较少使用。两者的区别如下:

这里要注意这个 KL divergence 并不是参数之间的距离,而是 actions 之间的距离。
PPO2 不使用 KL 散度,而是利用一个 clip 函数来保证差异不大。
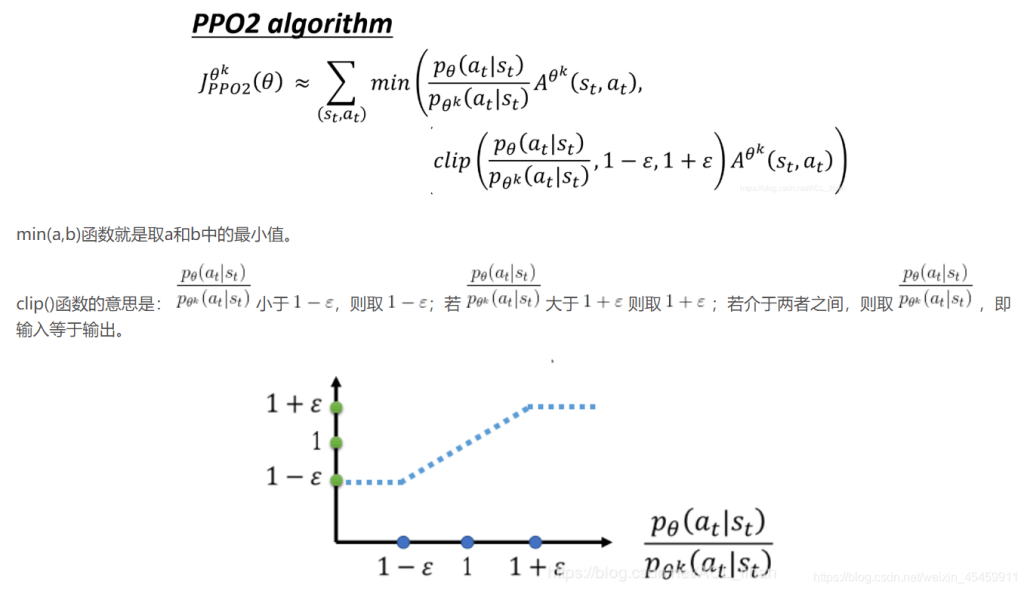
PPO2 通过引入了 Clip 函数,使第二项,即蓝色的虚线必须在 1 – ϵ 和 1 + ϵ 之间。
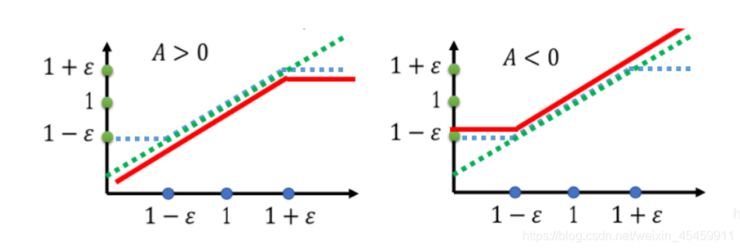
简单总结:
- TRPO 使用了 KL divergence(KL散度)作为约束
- PPO 将 KL 散度放到目标函数
- PPO2 不适用 KL 散度,而是使用 clip 函数
————————————————
版权声明:本文为CSDN博主「工藤旧一」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:#